Software development technologies become popular when they are heavily used, relied upon, and offer tangible benefits. Popularity in tech is not hype.
So, for businesses considering undertaking development in 2026, knowing the emerging software development technologies and tools is key to building a system that is future-proof. Because most of these technologies are here to stay.
Quick Overview of Most Popular Software Development Technologies and Tools in 2026
| Broader Category | Technology | Description | Popular Tools & Frameworks |
AI augmented development and AI integration | AI-Native Development Agents | Tools operating at the “intent layer” that compress the SDLC by translating developer descriptions into syntax, logic, and tests. | GitHub Copilot, Cursor, Codeium, Replit Ghostwriter |
| Multi-Agent AI Systems | Orchestration frameworks that decompose complex problems into specialized sub-tasks handled by collaborative AI agents. | LangChain, AutoGen, CrewAI | |
| AI/ML Integration Stack | Core toolkit for training, fine-tuning, and deploying LLMs and machine learning models in production environments. | PyTorch, TensorFlow, Hugging Face, OpenAI API | |
Cloud Infrastructure & Compute | Serverless & Cloud-Native Infrastructure | Abstraction layers that eliminate manual server management, enabling event-driven execution of functions and containers. | AWS Lambda, Cloudflare Workers |
| Containers | Lightweight execution environments for packaging and scaling applications consistently across environments. | Docker, Kubernetes | |
| Hybrid & Multi-Cloud Architecture | Strategic use of multiple cloud providers to improve resilience, cost efficiency, and data sovereignty compliance. | AWS, Azure, Google Cloud Platform (GCP), Terraform | |
Frontend, Platforms & Application Development | Type-Safe Frontend & Performance Automation | Tools focused on reducing runtime errors and improving UI performance through strict typing and optimized rendering pipelines. | TypeScript, React Compiler, Next.js, Vite |
| Low-Code / No-Code Platforms | Visual development environments enabling faster application building without traditional full-stack coding. | Mendix, OutSystems, Bubble, Retool | |
| Programming Languages (Core) | Foundational languages used across modern software systems for frontend, backend, systems, and full-stack development. | JavaScript, TypeScript, Python, Go, Rust | |
| Security & DevSecOps | AI-Augmented Security (DevSecOps) | Automated systems providing continuous monitoring, threat detection, and secure-by-design development pipelines. | Snyk, Darktrace, CrowdStrike Falcon, Intel SGX |
| Data & State Layer | Database technologies | Infrastructure enabling real-time synchronization, state management, and semantic retrieval for AI-driven applications. | Pinecone, Weaviate, Supabase, TanStack (Query/Router) |
10 Software Development Technologies Becoming Popular in 2026
The software development technologies trending in the US and globally are roughly the ones that promise better speed, lower costs, better security, and have capabilities to handle the complexity of modern software development.
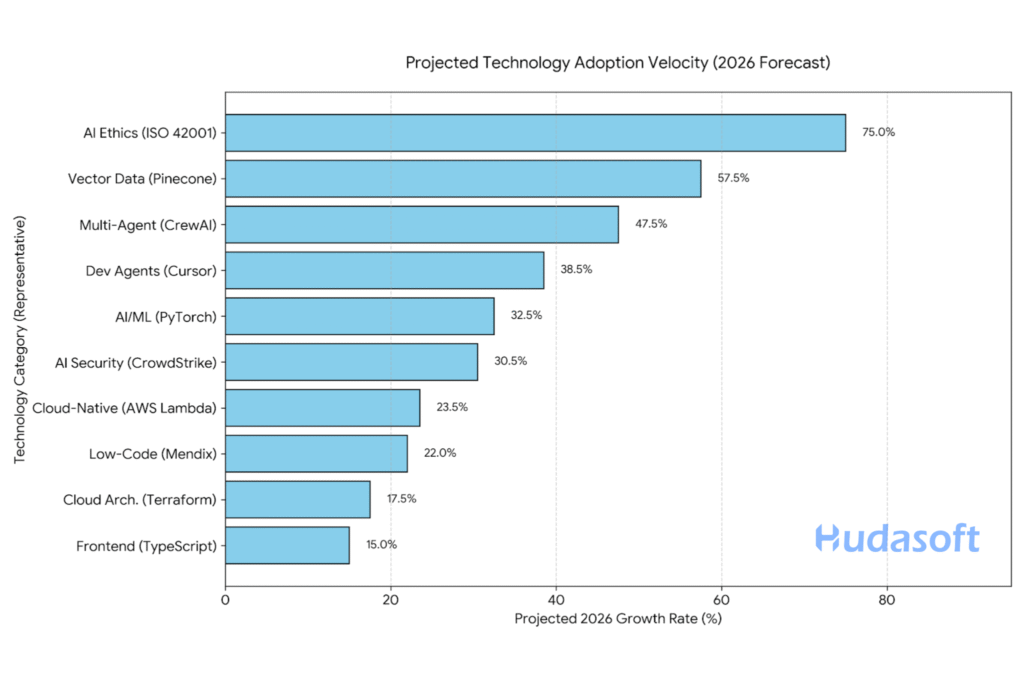
Disclaimer:
Growth projections are based on market intelligence from Gartner, Forrester, IDC, and IBM. Actual adoption rates may vary based on macroeconomic conditions, regulatory changes, and the pace of AI innovation.
1. AI-Native Development Agents
Approximately 23%–30% of software teams are now actively using AI agents for complex, multi-step tasks in production, and the usage is on the rise.
Here’s what Bill Gates has to say about AI agents in general (including those for development)

The first technology that deserves a mention in the list of most popular technologies in 2026 is AI-native development agents. This covers technologies like GitHub Copilot, Cursor, Codeium, and Replit Ghostwriter.
The reason these agents are becoming popular is simple. The economics of software development have changed. Development teams with smaller headcounts are competing for speed with established giants. Reliance on AI-native development agents is a direct response to that pressure. The appeal is not just autocomplete; it’s the ability to compress entire phases of the development lifecycle into a single interaction.
How do AI agents work for developers?
These tools operate at the intent layer. A developer describes what they want, and the agent handles translation into syntax, structure, and logic.
The exact way of working differs from technology to technology. For example, GitHub Copilot and Codeium use large language models fine-tuned on code repositories. They analyze the surrounding code context, including function signatures, variable names, imports, and comments, to predict what should come next. When a developer writes a comment describing a function, the model generates a plausible implementation by drawing on patterns from similar code it was trained on.
Cursor takes this further by embedding the LLM into the IDE at a deeper level. It can hold an entire codebase in context (or a compressed representation of it) and perform multi-step operations: refactoring a function, writing tests for it, and adjusting dependent files in one sequence. This is closer to orchestration than autocomplete.
Replit Ghostwriter is a partial exception. It’s designed within Replit’s cloud-based environment, so the agent has direct access to a live runtime. That means it can not only generate code but also run it, observe errors, and iterate. The feedback loop is tighter because execution happens in the same environment where the code is written.
Why this approach works
The SDLC traditionally involves a sequence of handoffs: requirements, design, implementation, testing, and deployment. These agents compress several of those phases into a single interface, reducing the friction between intention and working software.
The value this approach offers:
- reducing operational costs by up to 40%.
Popular Business Use Cases
- Legacy Code Modernization: Large enterprises in finance and insurance use agents to translate “monolith” systems (like COBOL or old Java) into modern microservices, reducing technical debt that previously took decades to clear.
- Rapid Product Prototyping: Startups use these agents to move from a verbal product description to a functional “Minimum Viable Product” (MVP) in days, allowing them to test market fit before hiring a full engineering team.
2. Multi-Agent AI Systems

Infographic source: towardsaihttps://towardsai.net/
Another major category making waves in 2026 is multi-agent AI systems. About 79% of enterprises report “planning” to incorporate multi-agent systems in their workflows.
Here’s how multi-agent systems are different from single AI agents: Single agents have a ceiling. They work well for contained tasks but struggle with problems that require sustained reasoning across multiple steps, external tool use, or coordination between different areas of expertise. Multi-agent systems decompose a complex problem into smaller, specialized sub-tasks to produce reliable output at each step.
The key technologies that allow multi-agent workflows are LangChain, AutoGen, and CrewAI.
How do multi-agent systems work?
These frameworks treat agents as collaborators. Each agent can have its own role, memory, and toolset. When they interact, the output of one becomes the input for another, allowing complex workflows to emerge from simpler components.
The exact architecture differs across frameworks. LangChain provides the underlying scaffolding for building agents that can use external tools, such as web search, databases, or APIs, and retain memory across multiple turns. The core idea is a “chain”: a sequence of calls where the model’s output is piped into the next step. Developers define which tools an agent can access, and the model learns to invoke them through a pattern called ReAct (Reasoning + Acting), where it alternates between thinking about what to do and doing it.
AutoGen, developed by Microsoft Research, takes a different approach. Rather than a fixed chain, it enables agents to converse with each other. A user-proxy agent represents the human, a coding agent writes code, an execution agent runs it, and a critic agent reviews the output. These agents message each other until they converge on a satisfactory result. The self-correcting loop is the distinguishing feature.
CrewAI adds structure on top of that conversational model by assigning formal roles, each with a defined goal and backstory. A “research analyst” agent behaves differently from a “copywriter” agent because their prompts are scoped differently. This makes workflows more predictable and easier to reason about when building production systems.
Why this approach works
Distributed teams outperform solo generalists on complex, multi-domain problems because they can parallelize work and apply specialized knowledge where it’s needed. Multi-agent systems apply the same logic to AI, scaling problem-solving horizontally rather than relying on a single model to do everything.
How do businesses benefit from AI agent- assisted development?
- Agents working in parallel can complete multi-step research, coding, and QA workflows up to 5x faster than sequential single-model pipelines. This allows development companies to ship software faster.
- The companies getting software built also benefit if their development partner deploys AI agents for development. They get lower-cost development and faster development.
3. AI/ML Integration Stack
The AI and ML integration stack is now a core part of the product development toolkit in 2026. The leading technologies here are PyTorch, TensorFlow, Hugging Face Transformers, and the OpenAI API.
AI has moved from a research discipline to a product requirement. Five years ago, most businesses consumed AI as a feature inside existing software. Now they are expected to build AI-powered experiences directly. That shift is driven by accessible APIs that removed the need for ML expertise, open-source model ecosystems that reduced the cost of experimentation, and user expectations shaped by consumer products like ChatGPT. Product and engineering teams that previously had no contact with machine learning are now expected to integrate language models, build fine-tuning pipelines, and evaluate model outputs.
How does the AI/ML integration stack work?
These tools cover different stages of the AI development cycle. PyTorch and TensorFlow are for training and fine-tuning models. Hugging Face is for accessing and deploying pre-trained models. The OpenAI API is for consuming production-grade models without managing infrastructure. Together, they span from research-level work to production deployment.
PyTorch is the dominant framework for ML research and custom model development, with over 63% of all AI training models built on PyTorch in the US.
It represents neural networks as computational graphs built from tensors (multi-dimensional arrays), and it computes gradients automatically through a process called autograd. Developers define a model’s architecture in Python, feed data through it in a forward pass, compute a loss that measures prediction error, and backpropagate the gradient to adjust the model’s weights. This process repeats until the model’s outputs improve. PyTorch’s dynamic computation graph makes it easier to debug than earlier frameworks, which is why most academic research now uses it.
TensorFlow, developed by Google, follows similar principles but was originally designed with production deployment as a priority. TensorFlow 2 adopted eager execution closer to PyTorch’s style, and wrapped its deployment tooling into the TensorFlow Extended (TFX) ecosystem. In practice, PyTorch has taken a large share of new projects, and TensorFlow’s usage is concentrated in organizations that built their ML infrastructure around it earlier.
Hugging Face provides a model hub and the transformers library, which offers a consistent interface for working with thousands of pre-trained models. A developer who wants to use a model for text classification, translation, or summarization can download it with a few lines of code and run inference immediately, without training anything. Hugging Face also supports fine-tuning, where a pre-trained model’s weights are further adjusted on a smaller, domain-specific dataset.
The OpenAI API is the exception in this stack because it does not give developers access to model internals. It exposes GPT-4 and related models through an HTTP interface. Developers send a prompt and receive a completion; everything else, including infrastructure, scaling, and model updates, is managed by OpenAI. This makes it the fastest path to production for teams that want AI capabilities without ML expertise, but it comes with tradeoffs: no access to model weights and dependency on a third-party service.
The value this approach offers:
- Hugging Face alone hosts over 2.4 to 2.5 million public models as of 2026, meaning most teams can find a pre-trained starting point rather than training from scratch, cutting development timelines from months to days
Software equipped with these technologies is capable of giving significantly more business value. The application of AI-powered software in marketing and large-scale companies in the private sector are just a few of the examples.
- Hyper-Personalized Marketing: Retailers integrate ML models directly into their apps to predict what a customer wants to buy next based on real-time browsing behavior, rather than just past purchases.
- Predictive Maintenance: Energy companies use these stacks to process data from power grids, predicting equipment failure weeks in advance to schedule repairs during low-demand periods.
4. Cloud Architecture (Hybrid / Multi-Cloud)
Hybrid and multi-cloud architecture has become the default for enterprise infrastructure planning in 2026. The key platforms are Amazon Web Services, Microsoft Azure, and Google Cloud Platform, with Terraform serving as the connective tissue across all three.
Organizations that built everything on a single cloud provider discovered the risks: price increases with limited negotiating leverage, regional outages with no failover, and service gaps in geographies where the provider has limited presence. Multi-cloud adoption accelerated as enterprises realized that vendor flexibility is a form of risk management. Regulatory requirements in some industries also require data to remain within specific geographic boundaries, which not all providers can satisfy equally.
How does a hybrid and multi-cloud architecture work?
AWS, Azure, and GCP offer overlapping but not identical capabilities. AWS has the broadest service catalog and the largest third-party ecosystem. Azure integrates tightly with Microsoft’s enterprise software stack, making it a natural choice for organizations already running Active Directory and Microsoft 365. GCP has strengths in data analytics and machine learning, partly because Google uses it internally for its own AI workloads.
Each platform delivers compute, storage, networking, databases, and AI services as APIs. The underlying infrastructure is physically distributed across regions (geographic areas with multiple data centers) and availability zones (isolated facilities within a region). Applications can be designed to fail over between zones or regions automatically if one becomes unavailable.
Terraform is what makes multi-cloud infrastructure manageable. It uses a declarative configuration language (HCL) where developers describe the desired state of their infrastructure: which virtual machines to create, what network rules to apply, and which services to connect. Terraform maintains a state file that tracks what has actually been provisioned, and it computes a difference between the desired and actual state when changes are made. The same configuration syntax works across AWS, Azure, GCP, and dozens of other providers, so teams do not need to learn separate tooling for each cloud.
What value do hybrid and cloud architecture technologies offer?
Cloud portability reduces dependency on any single vendor’s pricing, availability, and roadmap. Terraform makes that portability operationally viable by providing a single interface for managing infrastructure across providers.
Enterprises using multi-cloud strategies report 20-30% lower cloud costs through competitive pricing leverage and workload placement optimization, according to Gartner
When it comes to specific areas where hybrid architecture works
- Disaster Recovery & Redundancy: Airlines split their critical booking systems across two different cloud providers (e.g., AWS and Azure) to ensure that a single provider’s regional outage doesn’t ground their entire fleet.
- Data Sovereignty Compliance: Multi-national corporations keep sensitive local data on private clouds within specific countries to meet legal requirements, while using public clouds for general global operations.
5. FaaS Technologies for Serverless Computing
About 33-50% of US enterprises are using serverless infrastructure, due to its long-term cost-cutting benefits.
Under the umbrella of cloud and serverless computing, cloud providers like AWS and Azure come to mind. But we are not talking about that. The technologies we are discussing here are ones that come under the category of “serverless compute services”. These technologies allow code to be run without managing servers.
Major service providers in this space are Cloudflare Workers and AWS Lambda.
How do serverless computing technologies work?
In simple terms, cloud native technologies allow teams to ship code without thinking much about the machines it runs on.
AWS Lambda executes code in response to events, such as an HTTP request, a file upload, or a message in a queue. There are no servers to provision. The developer uploads a function, defines what triggers it, and Lambda handles everything else: spinning up an execution environment, running the code, and scaling to handle concurrent requests automatically. Billing is per invocation, so idle functions cost nothing.
Cloudflare Workers operates on a similar model but runs at the network edge. Meaning the code executes in data centers close to the user rather than in a central region. This reduces latency for globally distributed applications. Workers also use the V8 engine (the JavaScript runtime behind Chrome) rather than traditional Linux containers, which makes cold starts nearly instant compared to Lambda.
What benefits do serverless and cloud-native infrastructure offer to businesses?
- Organizations using serverless architectures report infrastructure management overhead reductions of 60-70% compared to traditional VM-based deployments
When it comes to specific use cases, these examples demonstrate the effectiveness of cloud native infrastructure in the most straightforward manner:
- Retailers use serverless functions to process millions of transactions during peak sales (like Black Friday) without paying for idle server capacity during the rest of the year.
- Manufacturing plants run “cloud-native” code directly on factory floor devices to analyze sensor data instantly, reducing latency for safety-critical shutoff systems.
6. Containers and Orchestration Technologies
Cloud native infrastructure is dependent on another subset of technologies to run effectively. These are broadly categorized as ‘container and orchestration’ technologies.
Around 93% of companies are using container technologies in 2026. The reason is simple. Container technologies allow for code to run across environments without any compromise on performance or security.
Here’s how containers and orchestration technologies work:
Container technologies like Docker let you package an application together with everything it needs to run. This includes code, runtime, libraries, and system tools. With this approach, the app works consistently across different environments.
You typically start with a container image, which is a lightweight, read-only template built from layered instructions (like a Dockerfile). When you run this image, it becomes a container, an isolated process running on your machine. Multiple containers can run on the same host without interfering with each other.
For managing many containers across systems, orchestration tools like Kubernetes come in. Kubernetes takes those containers and manages them at scale. It handles:
- Scheduling: Kubernetes looks at all available servers and chooses the best one for each container based on free CPU, memory, and workload. This ensures no single server is overloaded while others sit idle.
- Self-healing: If a container crashes or stops responding, Kubernetes automatically restarts it or replaces it with a new one. If a whole server fails, it moves those containers to other healthy servers.
- Scaling: When traffic increases, Kubernetes can spin up more copies of your application to handle the load. When demand drops, it removes extra copies to save resources.
- Rolling updates: When you release a new version of your app, Kubernetes gradually replaces old containers with new ones. This way, users don’t experience downtime, and if something goes wrong, it can quickly roll back to the previous version.
Developers declare the desired state of their system, and Kubernetes continuously works to maintain that state.
7. Type-Safe Frontend and Performance Automation
Frontend tooling has matured significantly, and in 2026, the dominant stack centers on TypeScript, the React Compiler, Next.js, and Vite.
The major challenge in frontend development has been managing growing complexity and maintaining performance. As applications scale, they become more prone to runtime errors and slower load times, both of which directly affect user experience and business outcomes.
To address the issue of complexity, tools like TypeScript and the React Compiler reduce uncertainty in the codebase. TypeScript catches errors during development instead of at runtime, preventing bugs from reaching production. The React Compiler improves performance by automatically avoiding unnecessary re-renders, removing the need for manual optimization.
For performance and efficiency, Next.js and Vite handle key bottlenecks. Next.js provides built-in features like routing and server-side rendering to ensure faster, well-structured applications. Vite focuses on speeding up the development process with near-instant updates, allowing teams to build and iterate much faster.
8. Low-Code / No-Code Platforms
Low-code and no-code platforms have graduated from a niche category to a mainstream development strategy in 2026. Leading platforms include Mendix, OutSystems, Bubble, and Retool.
There are far more software problems in the world than there are engineers to solve them. Internal tools, approval workflows, operations dashboards, customer portals: most organizations have a backlog of these projects that the engineering team never reaches because higher-priority product work takes precedence. Low-code and no-code platforms address that gap by allowing people who understand the business problem to build the solution themselves.
How do low-code and no-code platforms work?
These platforms trade flexibility for speed. They abstract away the programming layer and expose business logic through visual interfaces, drag-and-drop editors, and configurable components. For a large class of applications, particularly internal tools and structured workflows, that tradeoff is worth it.
Mendix and OutSystems are enterprise-grade platforms aimed at professional developers and business analysts working together. Both provide visual modeling environments where applications are built by configuring components and defining logic through flowcharts rather than writing code. Under the hood, they generate actual application code deployable to cloud infrastructure. They support complex data models, role-based access control, and integration with enterprise systems like SAP and Salesforce. OutSystems additionally includes built-in performance monitoring and automated code quality checks.
Bubble targets a different audience entirely. It is aimed at non-technical builders who want to create full-stack web applications without writing any code. The editor is entirely visual: users design the interface by placing elements on a canvas, define data types and their relationships, and write “workflows” (sequences of conditional logic) to handle user interactions. Bubble handles hosting, the database, and backend logic from a single interface. The tradeoff is that complex or performance-sensitive applications hit the limits of what Bubble can express fairly quickly.
Retool occupies a narrower niche: internal tools for technical teams. It connects directly to databases, APIs, and services, and provides a library of pre-built components (tables, forms, charts) that developers wire together with JavaScript snippets. It is not no-code; JavaScript is required for anything beyond basic interactions. But it is substantially faster than building an internal admin panel from scratch, which is the specific problem it is designed to solve.
Why this approach works
These platforms compress configuration into a visual layer that domain experts can operate. The result is that people with deep knowledge of a business problem can build solutions for it without waiting for engineering capacity.
The value this approach offers:
- Low-code development is estimated to be 5 to 10 times faster than traditional coding for standard business applications, according to Forrester Research
Popular Business Use Cases
- Business Operations Dashboards: Operations managers build their own custom tracking tools and approval workflows without submitting a ticket to the IT department, clearing massive internal backlogs.
- Field Service Mobile Apps: Logistics companies empower non-technical supervisors to build simple apps for drivers to log deliveries, capture signatures, and report vehicle issues directly from the road.
9. Programming languages
The programming language landscape is shifting. JavaScript, Python, and Java still dominate in terms of active codebases, but the languages gaining the most ground in 2026 are ones built around performance, safety, and predictability at scale. Two languages stand out in this shift: Rust and Zig.
Both are systems-level languages, meaning they operate close to the hardware without the safety net of a garbage collector or runtime. But they approach that space differently, and the reasons developers are reaching for them in 2026 are worth understanding.
How do these languages work?
Rust is built around a concept called ownership. Every piece of memory in a Rust program has a single owner at any given time, and when that owner goes out of scope, the memory is freed. No garbage collector. No manual malloc and free. The compiler enforces ownership rules at compile time, which means entire categories of bugs, use-after-free, null pointer dereferences, and data races are caught before the program ever runs.
This matters because most critical security vulnerabilities in production software trace back to memory mismanagement. Rust eliminates that class of risk structurally, not through discipline. The tradeoff is a steeper learning curve, particularly around the borrow checker, which enforces ownership rules and initially resists patterns that feel natural in other languages.
In practice, Rust code compiles to native binaries with performance comparable to C and C++. It has strong support for concurrency, and its type system makes it difficult to write unsafe concurrent code without explicitly opting into it.
Zig takes a different approach. It is designed around explicit control and simplicity. There is no hidden control flow, no operator overloading, no implicit memory allocation. If a function allocates memory, it takes an allocator as a parameter, making allocation visible and testable. Error handling is done through return values with explicit error types, not exceptions.
Zig is also notable for how it handles cross-compilation and C interoperability. It can compile C code directly, and its build system is capable of targeting multiple platforms without complex toolchain setup. This makes it useful for projects that need to run across different operating systems and hardware architectures without maintaining separate build pipelines.
Both languages are also seeing growing adoption in WebAssembly targets, where their lack of runtime overhead and precise memory control are an advantage over managed-memory languages.
What value do these languages offer?
- Rust’s memory safety model eliminates a category of bugs responsible for roughly 70% of critical security vulnerabilities in systems software, according to Microsoft and Google’s analysis of their own codebases.
Where do these languages offer practical solutions?
- High-Performance Infrastructure: Cloud providers and database companies use Rust to build core infrastructure, from storage engines to network proxies, where latency is measured in microseconds and memory bugs would be catastrophic.
- Embedded and IoT Systems: Manufacturers use Zig to write firmware for constrained devices where the entire codebase must run in kilobytes of memory, and cross-platform portability is a hard requirement.
10. AI-Augmented Security (DevSecOps)
Security once relied on manual, periodic checks. Now it requires continuous, AI-powered monitoring. This approach allows for the detection of vulnerabilities and allows developers to respond to threats in real time across code, infrastructure, and networks. The shift is driven by a paradigm called DevSecOps.
This approach allows developers to integrate security practices throughout the entire development lifecycle. The benefits over traditional security approaches are significant, which is why many businesses are adopting DevSecOps.
- The most obvious advantage of this approach is early detection of vulnerability: during the coding stage, instead of being highlighted by the end of the development cycle.
- Moreover, multiple checks ensure fewer vulnerabilities overall. Where fewer checks had the risk of vulnerabilities being ignored.
The major tools enabling this shift include. Snyk, Darktrace, CrowdStrike Falcon, and hardware-level solutions like Intel SGX.
How do AI-augmented security tools work?
Each tool covers a different layer of the security stack. Some focus on the code itself; others on network traffic or endpoint activity. Together, they push security from a gate at the end of the deployment pipeline to a continuous process that runs throughout development and production.
Snyk integrates into the development workflow to scan code, container images, and open-source dependencies for known vulnerabilities. When a developer adds a library with a security flaw, Snyk flags it in the IDE, the pull request, or the CI pipeline before the code reaches production. It pulls from its own vulnerability database and cross-references with sources like the National Vulnerability Database.
Darktrace uses unsupervised machine learning to build a behavioral baseline for every device and user in a network. Rather than matching traffic against a list of known threats, it learns what “normal” looks like for a specific environment and flags deviations. This approach is designed to catch novel attacks and insider threats that signature-based systems would miss.
CrowdStrike Falcon is an endpoint detection and response (EDR) platform. A lightweight agent runs on each device and streams telemetry to CrowdStrike’s cloud, where machine learning models analyze it for malicious patterns. Because the analysis happens in the cloud rather than on the device, Falcon can correlate signals across an entire organization’s fleet and identify threats that would be invisible if each endpoint were monitored in isolation.
Intel SGX is the exception in this list. It is a hardware-level technology that creates encrypted memory regions called enclaves. Code and data inside an enclave cannot be read or modified by the operating system, hypervisor, or any other process on the machine, even one with root privileges. This is particularly useful for processing sensitive data in cloud environments where the physical server is controlled by a third party.
Why this approach works
Security that runs only at deployment checkpoints cannot keep up with continuous delivery pipelines that ship code multiple times a day. These tools embed security into the development workflow and the runtime environment, which means threats are caught earlier and with less manual intervention.
The value this approach offers:
- Organizations that integrate security into their CI/CD pipelines detect and remediate vulnerabilities up to 6x faster than those relying on post-deployment audits
Popular Business Use Cases
- Predictive Threat Detection: Banks use AI to analyze network logs in real-time, identifying “pre-attack” patterns that indicate a hacker is probing for weaknesses before an actual breach occurs.
- Automated Compliance Auditing: Healthcare companies use AI to scan every line of new code for HIPAA or GDPR violations, ensuring privacy compliance is “baked in” rather than checked after the fact.
11. Data Layer Evolution (State + AI Data)
The data layer is one of the areas where the most architectural change is happening in 2026.
Key technologies include TanStack Query, TanStack Router, Pinecone, Weaviate, and Supabase.
Modern applications have two distinct data problems. The first is synchronization: keeping the client UI consistent with server state in real time, across multiple users, without stale data.
The second is retrieval: finding contextually relevant information in large datasets when traditional keyword search is not precise enough. AI-powered features have made the second problem much more common because LLMs require relevant context to produce accurate outputs, and that context has to come from somewhere.
How do these data layer technologies work?
TanStack tools solve client-side state management for traditional server interactions. Pinecone and Weaviate solve semantic retrieval for AI workflows. Supabase provides a backend that supports both. They address different layers of the data problem but increasingly appear together in AI-augmented applications.
TanStack Query manages the lifecycle of server state on the client: fetching data, caching it, invalidating the cache when it becomes stale, and re-fetching in the background. Before libraries like this existed, developers managed these concerns manually with useEffect hooks and local state, which was error-prone and verbose. TanStack Query treats server state as a first-class concern with its own caching and synchronization logic.
TanStack Router extends the same philosophy to URL state and routing. It integrates type-safe route definitions, search parameter management, and data loading directly into the routing layer, eliminating a category of bugs that come from treating the URL as an afterthought.
Pinecone and Weaviate are vector databases. When an LLM processes text, it converts that text into a vector: a high-dimensional numerical representation that encodes semantic meaning. Similar concepts produce similar vectors. A vector database stores these representations and supports similarity search: given a query vector, find the stored vectors closest to it. This is what powers retrieval-augmented generation (RAG), where an application retrieves relevant documents from its own data before passing them to a model as context.
The distinction between Pinecone and Weaviate is architectural. Pinecone is a fully managed, purpose-built vector database with a narrow feature set optimized for speed and scale. Weaviate is open-source, can be self-hosted, and supports hybrid searches that combine vector similarity with structured filters, making it more flexible for complex retrieval requirements.
Supabase is a Postgres-based backend that provides a database, authentication, real-time subscriptions, file storage, and auto-generated REST and GraphQL APIs from a single service. Its real-time subscription feature uses Postgres’s logical replication to stream database changes to connected clients, which makes it practical for collaborative or live-updating applications.
Why this approach works
Applications that use LLMs cannot rely on static or pre-indexed data alone. They need to retrieve fresh, contextually relevant information at query time. This stack provides the infrastructure for doing that without rebuilding data management from scratch.
The value this approach offers:
- RAG systems built on vector databases consistently outperform base LLMs on domain-specific tasks, with studies showing up to 40% improvement in answer accuracy on proprietary knowledge bases
Popular Business Use Cases
- Contextual Knowledge Retrieval (RAG): Law firms use vector databases to allow AI to search across millions of private legal documents to find relevant case law, ensuring the AI’s answers are based on facts rather than “hallucinations.”
- Real-Time Collaborative Design: Modern creative agencies use these data layers to allow global teams to edit the same high-resolution 3D models or documents simultaneously with zero lag.
How To Find Software Development Companies That Use Modern and Relevant Technologies?
To find the right software development company using modern, future-relevant technologies, you need to evaluate three key areas: their portfolio, their technology stack, and their depth of expertise. This gives you a clear understanding of whether they are aligned with the technologies gaining traction in 2026 or simply relying on outdated approaches.
Companies that consistently keep their technology expertise up to date ensure their clients receive solutions built on the most modern and scalable foundations. Among such companies, Hudasoft is one that is growing in the U.S. market, known for delivering AI-powered software development services that are highly rated for their performance, reliability, and innovation.
Real-World Application of The Best Software Development Technologies by Hudasoft
In our work with Ibizi, we applied a combination of AI-powered development tools, cloud-native infrastructure, and modern programming languages to optimize development processes and deliver a scalable solution. By leveraging the best software development technologies like AI-native tools and serverless architecture, we were able to reduce development time by 40%, ensuring a more efficient product launch. For more on how these technologies came together, explore the full Ibizi case study.
Final Words
Popular technologies in 2026 are popular for a reason. By adopting these tools, businesses are able to make software that is faster to build, cheaper to run, more secure, and easier to scale. So following these trends isn’t about hype; it’s about choosing technologies that are proven to work and will likely stay relevant.
A big shift is happening with AI. Tools like AI coding agents and multi-agent systems are helping teams build software much faster by automating complex tasks and reducing manual work. At the same time, platforms like low-code/no-code are allowing even non-developers to create applications, which helps companies move more quickly without depending entirely on engineering teams.
Frequently Asked Questions About Software Development Technologies
Which software development technologies should enterprises prioritize in 2026?
Enterprises are prioritizing multi-cloud architecture, DevSecOps tooling, and AI/ML integration stacks. Legacy modernization using AI agents is also a high-ROI area for large organizations with aging codebases.
Which software development technologies are best for startups?
Startups benefit most from serverless infrastructure, low-code platforms for internal tooling, and AI-native development agents. These reduce the engineering headcount needed to ship a working product quickly.
What kinds of business tasks are multi-agent systems used for?
Software development, research automation, QA workflows, data analysis pipelines, and customer support escalation handling.
When should a business use the OpenAI API instead of building a custom model?
A business should use the OpenAI API instead of building a custom model when the team has no ML expertise, speed to production is a priority, and the use case does not require access to model weights or domain-specific training data.
What types of applications benefit most from serverless?
Applications that benefit most from serverless are those with unpredictable or spiky traffic patterns, where paying for idle server capacity makes no sense. Retailers processing millions of transactions during peak sales periods like Black Friday, and manufacturing plants running latency-sensitive code on factory-floor devices for real-time safety systems are two clear examples where serverless delivers measurable value.
Why do companies use containers instead of virtual machines?
Companies use containers because they package an application together with everything it needs to run, including code, runtime, libraries, and system tools, ensuring the app works consistently across different environments. According to DevOps Digest, around 93% of companies are using container technologies in 2026 because containers allow code to run across environments without compromising on performance or security.
Is Kubernetes necessary for every containerized application?
No. Kubernetes is built for managing containers at scale. It handles scheduling, self-healing, scaling, and rolling updates across multiple servers. For small applications running a single container or a handful of services, Kubernetes adds unnecessary complexity. It becomes necessary when the application grows to a point where managing containers manually across multiple servers becomes operationally unviable.
